
In light of ongoing technological advancements, the proliferation of smart devices continues persistently, leading to an exponential increase in data generation. Consequently, companies and organizations are compelled to undergo rapid digital transformation to remain competitive. Among the strategies proving most effective for adaptation is the use of data-driven decision-making processes.
The escalating volume of daily data production presents significant challenges for organizations tasked with its management. To extract meaningful insights, companies must possess the capability to efficiently store, process, and analyze vast datasets. Thus, it becomes imperative for every organization to invest in methods for integrating consistent and high-quality data into their systems to derive valuable insights crucial for informed decision-making.
In data environments, clean data that feeds the system can be achieved by measuring data quality metrics in the testing phase. In this article, we will explain some best practices for measuring the data quality of the system with the right metrics.
The Advantages of Data Management in Data Environments
In data analytics or machine learning endeavors, there are typically two primary components that encompass all stages: data management and the development of machine learning models or data visualization for business applications. Despite the latter being more widely recognized, teams should prioritize the former. This is because all efforts may be rendered futile from a business standpoint without a foundation of solid data engineering.
In practical scenarios, data originates from various sources, including sensor data or mobile app log eventsin diverse formats, time zones, and types. This diversity heightens the likelihood of encountering erroneous, messy, or inconsistent data. Consequently, data-focused organizations should construct robust data management systems capable of rectifying such discrepancies and cleansing raw data acquired from sources through automated pipelines. Such architectural frameworks not only save teams valuable time but also seamlessly integrate with other data resources or business applications, facilitating the provisioning of data to machine learning models or visualizations.

The Role of Data Quality in Data Management
In your organization, a high-quality data management system offers critical advantages such as time savings through the reduction of unnecessary development tasks and the prevention of erroneous business decisions. The latter is especially significant, as inconsistent data within the data management lifecycle can lead to misleading feedback for business teams, potentially resulting in significant losses for your organization.
Furthermore, organizations stand to acquire invaluable practical experience in constructing intricate architectures. This hands-on knowledge enables them to effortlessly incorporate best practices into future projects. Consequently, the development of a data management system can be expedited, streamlined, and made more effective.
Level Up Your AI Expertise! Subscribe Now:
![]()
![]()
Best Practices for Measuring Data Quality with Metrics
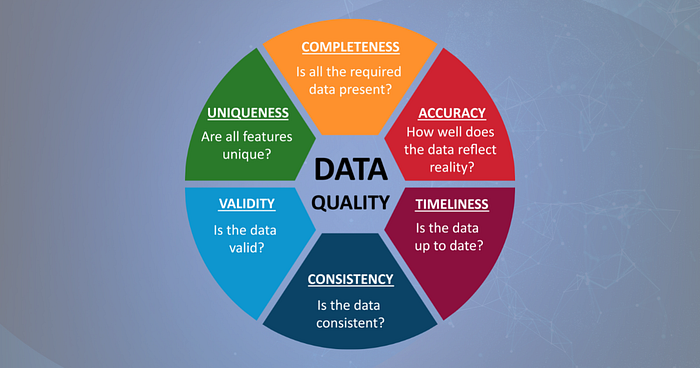
Ensuring data quality is paramount for the effectiveness of data systems or data-driven solutions geared towards meeting business objectives in projects. Acknowledging the importance of data analytics within organizations is crucial for producing high-quality data. In this endeavor, we will focus on developing some best practices to measure the quality of data using metrics that are built on top of the following data quality dimensions.
- Accuracy
- Completeness
- Consistency
- Validity
- Timeliness
- Uniqueness
- Relevance
Track Wrong Data Ratio
Erroneous, unexpected, or null data may originate from backend or mobile systems, constituting a potential occurrence within software architectures. To maximize data quality, it’s imperative to develop analytical pipelines capable of identifying and monitoring erroneous data and its rates over time through a dashboard. Continual enhancements to the efficiency of data platforms can be achieved by collaboratively pinpointing the sources of erroneous data with both technical and business teams.
Detect Missing Data Modeling
Data modeling is one of the foundational and crucial steps in data platforms. Employing the correct modeling approaches in architectures not only significantly influences data quality but also mitigates potential larger issues that could arise in the future. To ensure accurate data modeling, it’s essential to develop test pipelines.
For instance, in conducting a pricing analysis for package purchases, transaction IDs should be retained across all three models to facilitate the integration of customer country-package code and price information. Failure to adhere to such practices can render the data unusable due to incorrect data modeling.
Prevent Data Lag
In data streaming architectures, continuous data flow may encounter delays caused by sudden increases in load on data infrastructure. As a result, data lag and unavailability may occur. Data lag can be a nightmare for data teams because it may affect all analytic pipelines that are built on top of streaming raw data. To tackle this challenge, it’s crucial to incorporate a tracking algorithm into the data pipeline, empowering data teams to swiftly detect and resolve latency issues.
In-person conference | May 13th-15th, 2025 | Boston, MA
Join us on May 13th-15th, 2025, for 3 days of immersive learning and networking with AI experts.
🔹 World-class AI experts
🔹 Cutting-edge workshops
🔹 Hands-on Training
🔹 Strategic Insights
🔹 Thought Leadership
🔹 And much more!

Conclusion
In the evolving landscape of big data and machine learning, traditional Excel files have evolved into detailed data architectures like revenue dashboards and mobile app analytics reports. Despite their varying functionalities, their strength and value stem from the careful provision of high-quality data to interconnected systems. This article describes some best practices for measuring the quality of the data using the right metrics.
About the Author –
Kruti Chapaneri is an aspiring software engineer and tech writer with a strong interest in the intersection of technology and business. She is excited to use her writing skills to help businesses grow and succeed online in the competitive market. You can connect with her on Linkedin.






